RAG with Ollama
Demo Application: Local RAG Chatbot with Ollama and LlamaIndex
This project demonstrates how to create a local Retrieval Augmented Generation (RAG) chatbot using Ollama for running Large Language Models (LLMs) and LlamaIndex for data indexing and retrieval. The chatbot allows users to upload documents (PDFs, text files, JSON, HTML, DOCX, CSV) and ask questions about their content.
Overview
In today’s AI-driven world, accessing and processing information efficiently is crucial. This project leverages the power of local LLMs and vector store indexing to enable users to interact with their documents in a conversational manner. By combining Ollama’s ability to run LLMs locally with LlamaIndex’s robust data indexing, we create a powerful tool for knowledge retrieval and question answering.
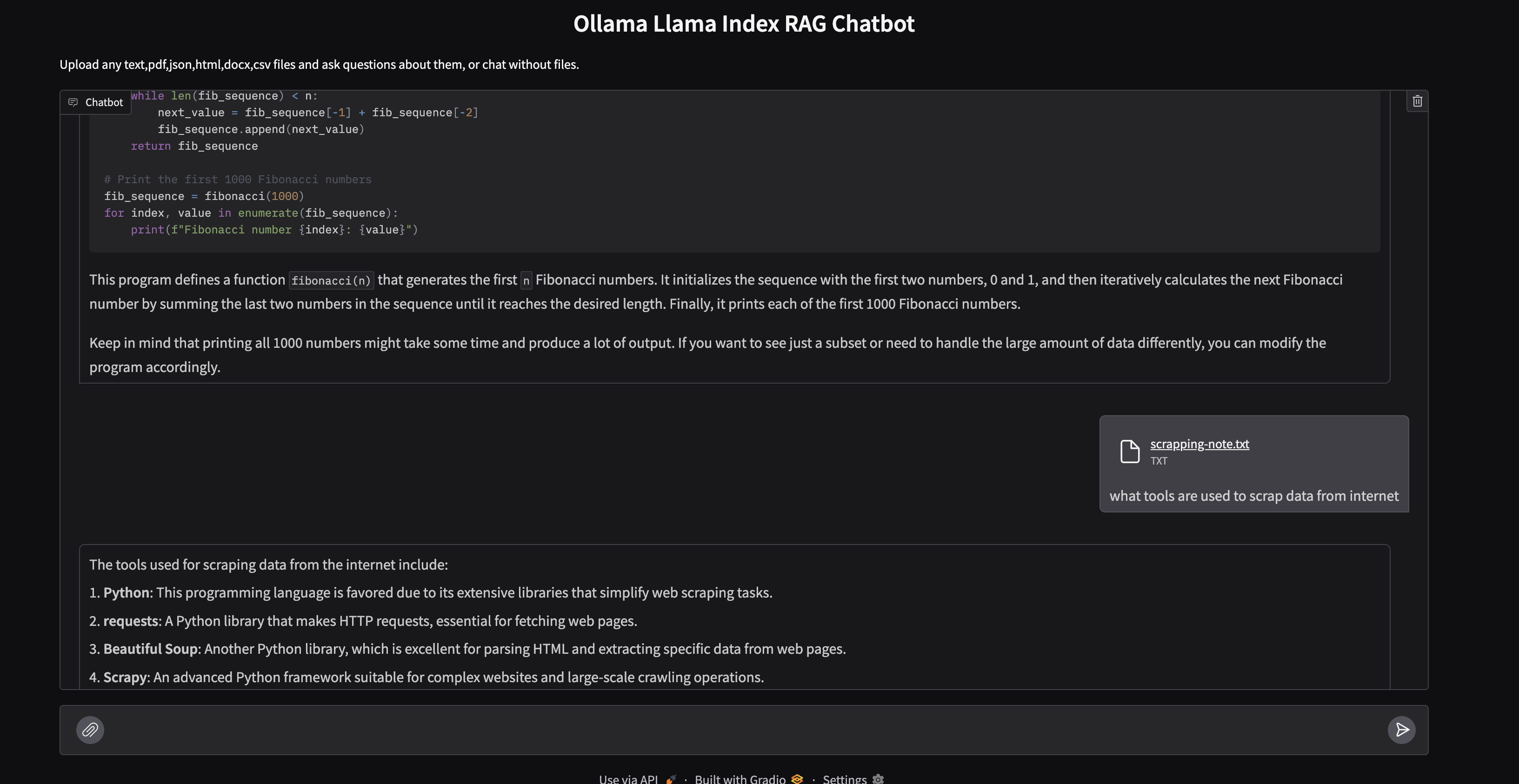
Features
- Local LLM with Ollama: Utilizes Ollama to run LLMs locally, ensuring data privacy and reducing reliance on external APIs.
- Document Upload and Processing: Supports various file formats (PDF, TXT, JSON, CSV, MD, HTML, DOCX) for document upload.
- LlamaIndex Integration: Employs LlamaIndex to index uploaded documents and perform efficient retrieval.
- Vector Store Indexing: Uses vector embeddings to represent document content, enabling semantic search and retrieval.
- Gradio Interface: Provides a user-friendly chat interface for interacting with the chatbot.
- Dynamic Model Detection: Automatically detects and uses a running Ollama model or defaults to
llama2:latest. - Timeout Client for Ollama: Includes a timeout feature for the Ollama client to handle long queries.
Dependencies
llama-index: For data indexing and retrieval.ollama: For running local LLMs.gradio: For creating the user interface.sentence-transformers: For generating document embeddings.
Setup and Installation
- Install Ollama:
- Follow the installation instructions on the official Ollama website to set up Ollama on your local machine.
- Pull an LLM:
- Open a terminal and pull the desired LLM using Ollama. For example:
ollama pull llama2
- Open a terminal and pull the desired LLM using Ollama. For example:
- Install Python Dependencies:
- Create a virtual environment (recommended):
python3 -m venv venv - Activate the virtual environment:
source venv/bin/activate(orvenv\Scripts\activateon Windows). - Install the required packages:
pip install llama-index ollama gradio sentence-transformers
- Create a virtual environment (recommended):
- Run the Script:
- Execute the Python script:
python rag-ollama-all-local.py
- Execute the Python script:
- Access the Chatbot:
- Open your web browser and navigate to the URL displayed in the terminal.
Running it locally
- Clone the repository
1 2
git clone https://github.com/cfkubo/ollama-rag-chat cd ollama-rag-chat
- Create a virtual environment and activate it
1 2
python3 -m venv venv source venv/bin/activate
- Install dependencies using pip
1
pip3 install -r requirements.txt
- Run ollama or use other ollama models
1
ollama run llama2:latest
- Login to Hugginface acount
1
huggingface-cli login
- Run the application
1
python3 rag-ollama-all-local.py
Code Explanation
The script performs the following key tasks:
- Imports Necessary Libraries: Imports required libraries for LLM interaction, data indexing, and user interface.
- Configures Logging: Sets up logging for debugging and monitoring.
- Defines Timeout Client: Creates a custom Ollama client with a timeout setting.
- Detects Running Ollama Model: Uses
ps -efto detect if an Ollama model is already running and uses it. - Configures Ollama LLM and Embedding Model: Initializes the Ollama LLM and HuggingFace embedding model.
- Configures LlamaIndex Settings: Sets the LLM and embedding model for LlamaIndex.
- Defines the
answerFunction:- Handles user queries and document uploads.
- If documents are uploaded, it uses LlamaIndex to index and query the documents.
- If no documents are uploaded, it uses the LLM directly to answer the query.
- Creates Gradio Interface: Sets up a chat interface using Gradio for user interaction.
- Launches the Gradio Application: Starts the Gradio server.
Usage
- Open the web interface.
- Upload documents using the file upload feature.
- Ask questions related to the uploaded documents.
- The chatbot will provide answers based on the document content.
- If no document is uploaded, you can still chat with the LLM directly.
Future Improvements
- Persistent Vector Store: Implement a persistent vector store to avoid re-indexing documents on each interaction.
- Enhanced Error Handling: Improve error handling and provide more informative error messages.
- User Authentication: Add user authentication for secure access.
- Improved User Interface: Enhance the user interface for a better user experience.
- Containerize: Update the application to run in Docker, k8s and Cloud Foundry.
This project provides a foundation for building powerful local RAG chatbots. By leveraging Ollama and LlamaIndex, you can create customized solutions for knowledge retrieval and question answering tailored to your specific needs.