Real-Time Sales Order Processing
Real-Time Sales Order Processing with Spring Boot, RabbitMQ, Spring Cloud Data Flow, PostgreSQL, Debezium, and GemFire
This document outlines a workflow for processing sales orders in real-time, leveraging a combination of Spring Boot, RabbitMQ, Spring Cloud Data Flow, PostgreSQL, Debezium, and GemFire.
Architecture Overview
The system follows these steps:
- Sales Order Generation (Spring Boot): A Spring Boot application generates sales order data.
- Message Queuing (RabbitMQ): These sales orders are published as JSON payloads to a RabbitMQ queue.
- Data Ingestion (Spring Cloud Data Flow): Spring Cloud Data Flow is used to create a pipeline that reads messages from the RabbitMQ queue and inserts them into a PostgreSQL table (
salesorders). - Data Transformation (PostgreSQL): PostgreSQL triggers and stored procedures are used to automatically process new entries in the
salesorderstable. This involves parsing the JSON payload and populating a denormalized table (salesorders_read) with individual columns. - Change Data Capture (Debezium & Spring Cloud Data Flow): Spring Cloud Data Flow, utilizing a Debezium source connector, captures change data events from the
salesorders_readtable in PostgreSQL. - Real-Time Data Sink (GemFire): Changes captured by Debezium are then written in real-time to an “orders” region in GemFire.

Prerequisites
Before you begin, ensure you have the following installed and running:
- Docker: For containerizing the infrastructure components.
- Java Development Kit (JDK): For running Spring Boot and Spring Cloud Data Flow.
- Maven: For building Spring Boot applications.
- Spring Cloud Data Flow Server: Set up and running. You can follow the official Spring Cloud Data Flow documentation for installation.
Setting Up the Infrastructure
Start PostgreSQL with WAL Replication:
1
docker run -d --name postgres -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres debezium/example-postgres:2.3.3.Final
Create a Docker Network for GemFire:
1
docker network create gf-network
Start GemFire Locator:
1
docker run -e 'ACCEPT_TERMS=y' -d --name gf-locator --network=gf-network -p 10334:10334 -p 1099:1099 -p 7070:7070 gemfire/gemfire:9.15.6 gfsh start locator --name=locator1 --jmx-manager-hostname-for-clients=127.0.0.1 --hostname-for-clients=127.0.0.1
Start GemFire Server:
1
docker run -e 'ACCEPT_TERMS=y' -d --name gf-server1 --network=gf-network -p 40404:40404 gemfire/gemfire:9.15.6 gfsh start server --name=server1 --locators=gf-locator\[10334\] --hostname-for-clients=127.0.0.1
- Run rabbitmq in docker
1 2 3 4
docker network create rmq-network docker run -d --hostname my-rabbit ---name rabbitmq --network rmq-network -p 5552:5552 -p 15672:15672 -p 5672:5672 rabbitmq:3-management
- Enable RabbitMQ Streams Plugin
1 2
docker exec rabbitmq rabbitmq-plugins enable rabbitmq_stream docker exec rabbitmq rabbitmq-plugins enable rabbitmq_stream_management
- sample output from RabbitMQ after enabling stream plugin
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
rabbitmq_stream_management Enabling plugins on node rabbit@d212bb73a912: rabbitmq_stream rabbitmq_stream_management The following plugins have been configured: rabbitmq_management rabbitmq_management_agent rabbitmq_prometheus rabbitmq_stream rabbitmq_stream_management rabbitmq_web_dispatch Applying plugin configuration to rabbit@d212bb73a912... The following plugins have been enabled: rabbitmq_stream rabbitmq_stream_management started 2 plugins.
Database Schema and Logic (PostgreSQL)
Execute the following SQL scripts in your PostgreSQL database (postgres database created by the Docker container):
- DDL for salesorders,saleorders_read table
- Stored procedure that load data from salesorders to salesorders_read
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
CREATE SEQUENCE IF NOT EXISTS public.salesorders_order_id_seq;
CREATE TABLE IF NOT EXISTS public.salesorders (
order_id integer NOT NULL DEFAULT nextval('salesorders_order_id_seq'::regclass),
payload character varying(1000) COLLATE pg_catalog."default",
CONSTRAINT salesorders_pkey PRIMARY KEY (order_id)
);
CREATE OR REPLACE FUNCTION public.sales_order_trigger_func()
RETURNS TRIGGER
LANGUAGE plpgsql
AS $$
BEGIN
-- Call the stored procedure to process the order data
CALL public.process_sales_order(NEW.order_id, NEW.payload);
RETURN NEW;
END;
$$;
CREATE OR REPLACE TRIGGER sales_order_update_trigger
AFTER INSERT OR UPDATE
ON public.salesorders
FOR EACH ROW
EXECUTE FUNCTION public.sales_order_trigger_func();
CREATE TABLE IF NOT EXISTS public.salesorders_read
(
order_id integer,
product character varying(255) COLLATE pg_catalog."default",
price numeric(10,2),
quantity integer,
ship_to character varying(50) COLLATE pg_catalog."default",
payment_method character varying(50) COLLATE pg_catalog."default",
order_date date,
address character varying(50) COLLATE pg_catalog."default",
store_name character varying(50) COLLATE pg_catalog."default",
store_address character varying(50) COLLATE pg_catalog."default",
sales_rep_name character varying(50) COLLATE pg_catalog."default",
CONSTRAINT salesorders_read_pkey PRIMARY KEY (order_id)
);
CREATE OR REPLACE PROCEDURE public.process_sales_order(order_id INT, payload TEXT)
LANGUAGE plpgsql
AS $$
DECLARE
product VARCHAR(255);
price NUMERIC(10, 2);
quantity INT;
ship_to VARCHAR(50);
payment_method VARCHAR(50);
order_date DATE;
address VARCHAR(50);
store_name VARCHAR(50);
store_address VARCHAR(50);
sales_rep_name VARCHAR(50);
BEGIN
-- Extract values using regular expressions (assuming payload format: product='...', price=..., ...)
product := REGEXP_REPLACE(payload, '.*product=''([^'']*)''.*', '\1');
price := REGEXP_REPLACE(payload, '.*price=([\d\.]+).*', '\1')::NUMERIC(10, 2);
quantity := REGEXP_REPLACE(payload, '.*quantity=(\d+).*', '\1')::INT;
ship_to := REGEXP_REPLACE(payload, '.*shipTo=''([^'']*)''.*', '\1');
payment_method := REGEXP_REPLACE(payload, '.*paymentMethod=''([^'']*)''.*', '\1');
order_date := REGEXP_REPLACE(payload, '.*orderDate=([\d\-]+).*', '\1')::DATE;
address := REGEXP_REPLACE(payload, '.*address=''([^'']*)''.*', '\1');
store_name := REGEXP_REPLACE(payload, '.*storeName=''([^'']*)''.*', '\1');
store_address := REGEXP_REPLACE(payload, '.*storeAddress=''([^'']*)''.*', '\1');
sales_rep_name := REGEXP_REPLACE(payload, '.*salesRepName=''([^'']*)''.*', '\1');
-- Insert or update the salesorders_read table
INSERT INTO public.salesorders_read (
order_id, product, price, quantity, ship_to, payment_method,
order_date, address, store_name, store_address, sales_rep_name
) VALUES (
order_id, product, price, quantity, ship_to, payment_method,
order_date, address, store_name, store_address, sales_rep_name
)
ON CONFLICT (order_id) DO UPDATE SET
product = EXCLUDED.product,
price = EXCLUDED.price,
quantity = EXCLUDED.quantity,
ship_to = EXCLUDED.ship_to,
payment_method = EXCLUDED.payment_method,
order_date = EXCLUDED.order_date,
address = EXCLUDED.address,
store_name = EXCLUDED.store_name,
store_address = EXCLUDED.store_address,
sales_rep_name = EXCLUDED.sales_rep_name;
EXCEPTION
WHEN others THEN
RAISE NOTICE 'Error processing order %: %', order_id, SQLERRM;
END;
$$;
CREATE TABLE IF NOT EXISTS public.salesorders_fraud
(
order_id integer,
product character varying(255) COLLATE pg_catalog."default",
price numeric(10,2),
quantity integer,
ship_to character varying(50) COLLATE pg_catalog."default",
payment_method character varying(50) COLLATE pg_catalog."default",
order_date date,
address character varying(50) COLLATE pg_catalog."default",
store_name character varying(50) COLLATE pg_catalog."default",
store_address character varying(50) COLLATE pg_catalog."default",
sales_rep_name character varying(50) COLLATE pg_catalog."default",
CONSTRAINT salesorders_fraud_pkey PRIMARY KEY (order_id)
);
Save the above logic to bootstrap.sql
1
docker exec -i postgres psql -U postgres postgres < bootstrapsql
Spring Boot Application
You’ll need a Spring Boot application that generates sales order data in a specific format (matching the regular expressions in the PostgreSQL stored procedure) and sends it as JSON to a RabbitMQ queue.
Demo Application you can leverage: Sales Order Generator
- Clone the repository:
1 2
git clone https://github.com/cfkubo/spring-boot-random-data-generator cd random-data-generator
- Build the project:
1
mvn clean install
Configure RabbitMQ: Update the
application.propertiesfile with your RabbitMQ connection details.- Run the application:
1
mvn spring-boot:run
Usage
The application will generate random sales orders and send them to RabbitMQ. sThe application also logs the details of each generated order.
Example Sales Order Payload (as a String that will be embedded in JSON):
1
product='Laptop', price=1200.50, quantity=1, shipTo='Home', paymentMethod='Credit Card', orderDate=2025-03-27, address='123 Main St', storeName='Tech Store', storeAddress='456 Oak Ave', salesRepName='John Doe'
The Spring Boot application flow:
- Establish a connection to RabbitMQ.
- Define a queue (e.g., salesOrderQuorumQueue).
- Generate sales order data periodically or on demand.
- Convert the sales order data into a JSON payload (where the above string is likely a value of a field).
- Publish the JSON payload to the RabbitMQ queue.
Spring Cloud Data Flow(SCDF)
Spring Cloud Data Flow is provides an dashabord and shell to deploy the data pipelines. You can leverge the below file or download the never versions if needed.
Download SCDF Server, Skipper and Shell
1
2
3
4
5
wget https://repo.maven.apache.org/maven2/org/springframework/cloud/spring-cloud-dataflow-server/2.11.5/spring-cloud-dataflow-server-2.11.5.jar
wget https://repo.maven.apache.org/maven2/org/springframework/cloud/spring-cloud-dataflow-shell/2.11.5/spring-cloud-dataflow-shell-2.11.5.jar
wget https://repo.maven.apache.org/maven2/org/springframework/cloud/spring-cloud-skipper-server/2.11.5/spring-cloud-skipper-server-2.11.5.jar
Run SCDF Skipper
1
java -jar spring-cloud-skipper-server-2.11.5.jar
Run SCDF Server
1
java -jar spring-cloud-dataflow-server-2.11.5.jar
Run SCDF Shell
1
java -jar spring-cloud-dataflow-shell-2.11.5.jar
Access SCDF Server Dashboard
1
http://localhost:9393/dashboard
Import the source and sink applicaiton
You will define two Spring Cloud Data Flow pipelines:
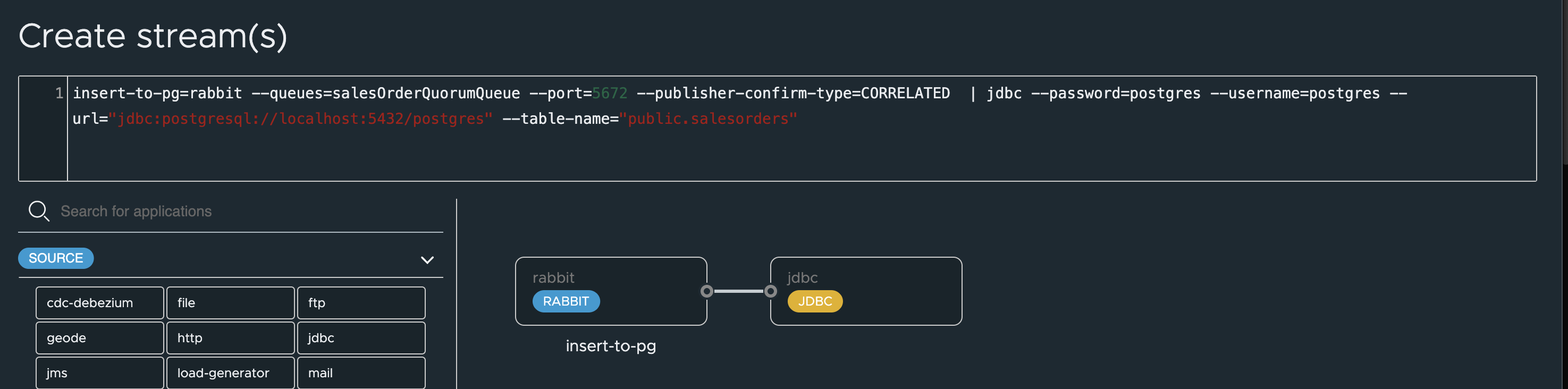
RabbitMQ to PostgreSQL
This pipeline reads from the RabbitMQ queue and writes to the salesorders table in PostgreSQL.
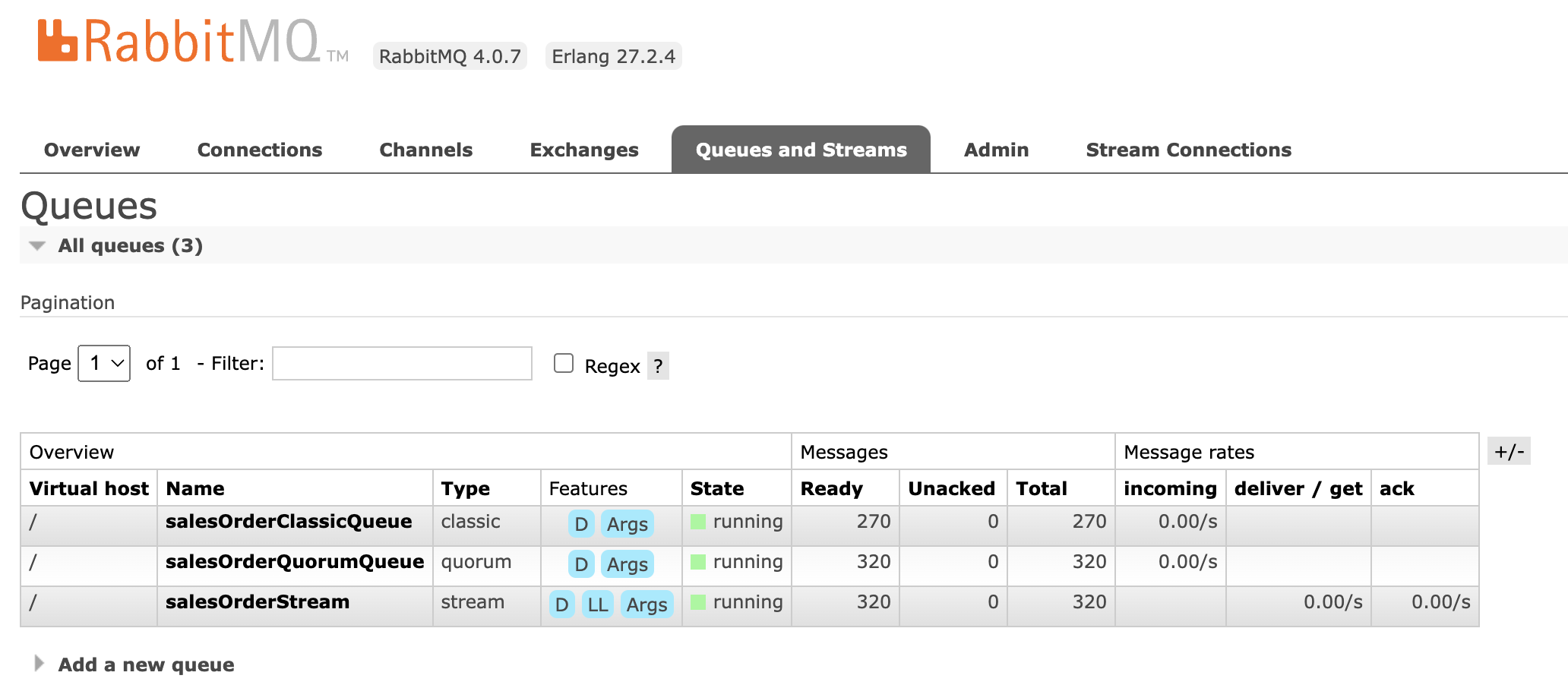
- rabbit (Source): Configured to connect to your RabbitMQ instance and consume messages from the salesOrderQuorumQueue.
- jdbc (Sink): Configured to connect to your PostgreSQL database and insert the received JSON payload into the public.salesorders table’s payload column.
- Register the necessary Spring Cloud Stream applications (RabbitMQ Binder and JDBC Sink) in your Spring Cloud Data Flow server.
1
insert-to-pg=rabbit --queues=salesOrderQuorumQueue --port=5672 --publisher-confirm-type=CORRELATED | jdbc --password=postgres --username=postgres --url="jdbc:postgresql://localhost:5432/postgres" --table-name="public.salesorders"
PostgreSQL CDC to GemFire
This pipeline captures changes from the salesorders_read table in PostgreSQL and writes them to GemFire.
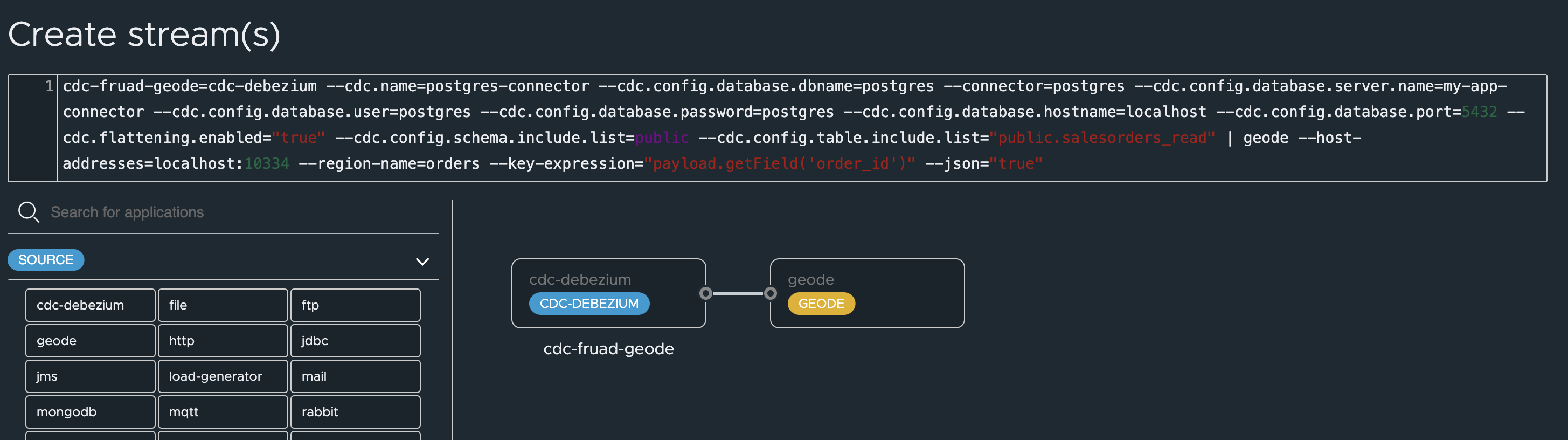
- cdc-debezium (Source): A Debezium source connector configured to:
- Connect to the PostgreSQL database.
- Monitor the public.salesorders_read table for changes.
- Use the specified database credentials and connection details.
- Enable flattening of the Debezium message payload.
- geode (Sink): A GemFire sink connector configured to:
- Connect to the GemFire locator at localhost:10334.
- Write data to the “orders” region.
- Use the order_id field from the Debezium payload as the key in the GemFire region.
- Send the entire payload as a JSON value.
- Register the necessary Spring Cloud Stream applications (Debezium Source and GemFire Sink) in your Spring Cloud Data Flow server.
1
cdc-fruad-geode=cdc-debezium --cdc.name=postgres-connector --cdc.config.database.dbname=postgres --connector=postgres --cdc.config.database.server.name=my-app-connector --cdc.config.database.user=postgres --cdc.config.database.password=postgres --cdc.config.database.hostname=localhost --cdc.config.database.port=5432 --cdc.flattening.enabled="true" --cdc.config.schema.include.list=public --cdc.config.table.include.list="public.salesorders_read" | geode --host-addresses=localhost:10334 --region-name=orders --key-expression="payload.getField('order_id')" --json="true"
Configuring GemFire
Connect to the GemFire Locator using gfsh:
1
docker exec -it gf-locator gfsh
1
connect
Create the “orders” Region:
1
create region --name=orders --type=PARTITION
Running the Workflow
- Start the Spring Boot Sales Order Generator application. This will begin publishing sales order messages to the RabbitMQ queue.
- Deploy the “RabbitMQ to PostgreSQL” Spring Cloud Data Flow stream. This will start consuming messages and inserting data into the salesorders table.
- Observe PostgreSQL: As data is inserted into salesorders, the sales_order_update_trigger will fire, calling the process_sales_order stored procedure. This will parse the payload and populate the salesorders_read table.
- Deploy the “PostgreSQL CDC to GemFire” Spring Cloud Data Flow stream. This will connect to PostgreSQL via Debezium and start capturing changes in the salesorders_read table.
- Observe GemFire: As changes occur in salesorders_read, Debezium will emit change events, and the GemFire sink will write these events to the “orders” region in GemFire.
Verifying the Data in GemFire
You can use gfsh to query the “orders” region in GemFire:
Connect to the GemFire Locator:
1
docker exec -it gf-locator gfsh
1
connect
Query the “orders” Region:
1
query --query="select * from /orders"
You should see the sales order data (as JSON) that originated from your Spring Boot application, flowed through RabbitMQ and PostgreSQL, and was captured by Debezium and written to GemFire.
Conclusion
This workflow demonstrates a powerful and scalable approach to real-time data processing. By combining Spring Boot for application logic, RabbitMQ for asynchronous communication, Spring Cloud Data Flow for building data pipelines, PostgreSQL for persistent storage and data transformation, Debezium for change data capture, and GemFire for a high-performance in-memory data grid, you can build responsive and data-driven applications. This architecture allows for decoupling of services, efficient data transformation, and real-time data availability for downstream consumers.
Reference
- Event Streaming Showcase by Gregory Green