Building a reliable and scalable messaging system with RabbitMQ 🐰
🚀🐰📦 Building a reliable and scalable messaging system with RabbitMQ 🚀🐰📦
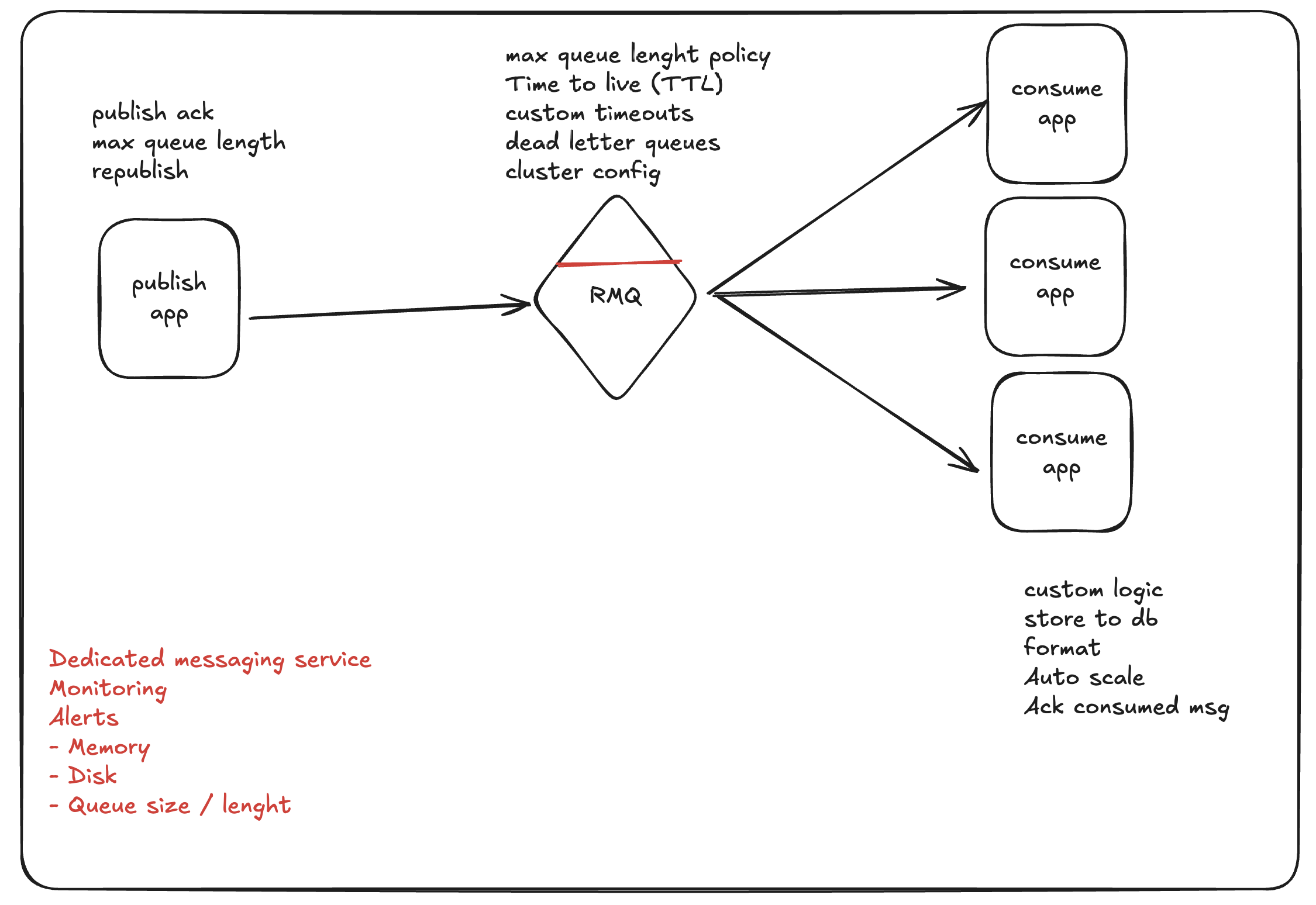
Building a reliable and scalable messaging system with RabbitMQ requires a thoughtful approach beyond just connecting a producer and a consumer. This blog post outlines best practices for the RabbitMQ server, producer applications, and consumer applications to ensure a highly reliable pub/sub architecture. We’ll leverage the concepts shown in the provided diagram and your sample applications to cover key areas like message durability, high availability, and consumer resilience.
1. The RabbitMQ Server: Your Messaging Backbone ⚙️
The RabbitMQ server isn’t just a simple message broker; it’s a powerful tool that needs careful configuration to guarantee message delivery.
High Availability and Durability For production environments, a single RabbitMQ node is a single point of failure. To ensure high availability and prevent data loss, you must set up a RabbitMQ cluster. A cluster replicates queues and data across multiple nodes.
Quorum Queues: This is the recommended queue type for reliability. Quorum queues use the Raft consensus algorithm to ensure data is replicated to a majority of nodes before an acknowledgment is sent. This prevents data loss even if a minority of nodes fail. Your quorum.transactions example is a great start.
Durable Exchanges and Queues: All queues and exchanges should be declared as durable. This ensures they survive a RabbitMQ server restart.
Persistent Messages: When a message is published, the producer should set the delivery_mode to 2 (persistent). This tells RabbitMQ to write the message to disk, ensuring it survives a broker restart.
Managing Backpressure and Unprocessed Messages
Leverage policies for max-length and overflow are excellent for managing backpressure.
Queue Length Policies: By setting a max-length, you prevent a queue from growing indefinitely and consuming all server memory. The reject-publish overflow strategy tells RabbitMQ to reject new messages when the queue is full, pushing the responsibility back to the producer.
These policies define message limits and overflow behavior for your queues. This is crucial for preventing queues from growing indefinitely and consuming excessive memory.
1
2
3
4
5
6
7
8
9
10
11
rabbitmqctl set_policy q-pol "quorum.transactions" \
'{"max-length":1000,"overflow":"reject-publish"}' \
--apply-to queues
rabbitmqctl set_policy s-pol "stream.transactions" \
'{"max-length":1000,"overflow":"reject-publish"}' \
--apply-to queues
rabbitmqctl set_policy c-pol "classic.transactions" \
'{"max-length":10000,"overflow":"reject-publish"}' \
--apply-to queues
Dead Letter Queues (DLQ): Messages can fail for many reasons (e.g., malformed data, consumer bugs). Instead of dropping them, configure a queue with a dead letter exchange. When a message is rejected, expires, or is dead-lettered due to a queue length policy, it’s routed to a dedicated DLQ. This allows you to inspect and reprocess failed messages later, preventing data loss.
2. The Producer Application: Ensuring Delivery 🤝
The producer’s job is not just to send a message but to do so with certainty.
For a practical example of a producer application, check out this Spring Boot project: https://github.com/yourusername/springrmqtransaction.git
Publisher Confirms (Publish Acknowledgment) RabbitMQ has a feature called publisher confirms. When enabled, the broker sends an acknowledgment back to the producer after a message has been accepted. This confirms that the message has safely reached the broker and been routed to its queues.
If the broker cannot deliver the message (e.g., no matching queue for a mandatory message, or a queue is full with reject-publish policy), it can send a negative acknowledgment (nack).
Your producer application should implement logic to handle these nacks by retrying the publish or logging the failure.
Transactions vs. Confirms While RabbitMQ also supports transactions, they are extremely slow and are not recommended for high-throughput scenarios. Publisher confirms are the modern, asynchronous, and performant way to ensure message delivery.
Configuration Your rabbitmqctl commands for setting queue policies are a fantastic way to enforce server-side rules. For the producer, ensuring messages are durable is a key step.
1
2
3
4
5
// Example in Spring AMQP for persistent messages
rabbitTemplate.convertAndSend(exchangeName, routingKey, message, m -> {
m.getMessageProperties().setDeliveryMode(MessageDeliveryMode.PERSISTENT);
return m;
});
3. The Consumer Application: Processing with Resilience 🛡️
The consumer application is the final link in the chain, and its reliability is critical. Your consumer application, with its use of manual acknowledgment and configurable concurrency, is on the right track.
For a practical example of a consumer application with a monitoring dashboard, refer to this Spring Boot project: https://github.com/cfkubo/spring-rmq-consumer
Manual Acknowledgments This is a cornerstone of reliable messaging. As your code shows, by using manual acks, a message is only removed from the queue after the consumer has successfully processed it.
channel.basicAck(): The message was processed successfully.
channel.basicNack() or channel.basicReject(): The message failed to be processed. This can be configured to either requeue the message (if a transient error) or send it to the Dead Letter Queue (if a permanent error).
Concurrency and Prefetch Concurrency: The number of concurrent consumers on a single channel. Setting this value correctly allows you to scale message processing. Too high, and you might overload your application or database.
Prefetch (QoS - Quality of Service): The number of unacknowledged messages a consumer can receive at a time. A low prefetch value ensures messages are distributed more evenly among multiple consumers, preventing one fast consumer from starving others. A high prefetch value is good for consumers that can process messages very quickly.
Consumer Timeouts The consumer-timeout policy you included is a crucial feature. It protects against “stuck” consumers that hold onto a message but never acknowledge it, effectively blocking the queue. If a consumer holds a message longer than the timeout, RabbitMQ will close the channel, and the message can be delivered to another consumer.
This policy ensures that consumers don’t hold messages for too long without acknowledging them. If a consumer fails, this setting can help release the message back to the queue for another consumer to process.
1
rabbitmqctl set_policy all ".*" '{"consumer-timeout":5000}'
Idempotent Consumers Since a message might be redelivered due to a consumer failure, your consumer logic must be idempotent. This means processing the same message multiple times has no negative side effects. For example, if your consumer writes to a database, it should check if the record already exists before creating a new one.
4. Dedicated Monitoring and Observability 🔭
Monitoring is essential to a reliable system. Your diagram correctly identifies key metrics.
Dedicated Monitoring Service: Use tools like Prometheus and Grafana (as shown in your consumer’s README) to monitor:
Server Health: CPU, memory, and disk usage of RabbitMQ nodes.
Queue Metrics: messages_ready (backlog), messages_unacknowledged, and the queue_size over time. This is critical for identifying backpressure.
Consumer Performance: ack_rate, nack_rate, and redelivery_rate to understand consumer health and message processing speed.
Alerting: Set up alerts for critical thresholds, such as a queue size exceeding a certain limit or a node going offline.
By combining these server-side configurations with best practices for your producer and consumer applications, you can build a resilient pub/sub system that guarantees message delivery and gracefully handles failures.